
Oft liest man in Foren Die Datei muss als UTF-8 ohne BOM abgespeichert werden. Ist eine Textdatei zum Beispiel in ANSI abgespeichert, erfordert aber UTF-8 ohne BOM, kann dies zu den berühmt-berüchtigten Hieroglyphen führen.
Bei manch anderen nicht als UTF-8 ohne BOM abgespeicherten Dateien kann es passieren, dass man beim Aufruf der Website nur noch eine weiße Seite zu Gesicht bekommt. Der Grund hierfür ist simpel aber schwerwiegend: Erfordert eine Datei UTF-8 und wird mit BOM abgespeichert, werden in der Kopfzeile oder in Leerzeilen unsichtbare Zeichen eingefügt. Die Ausführung dieser Dateien liefert dann in der Regel ein fehlerhaftes Resultat.
Für das Bearbeiten solcher Dateien, empfiehlt sich ein Text-Editor, der das Konvertieren und Kodieren in UTF-8 ohne BOM beherrscht. In diesem Tipp beschreibe ich den Workflow mit Notepad++ (nicht zu verwechseln mit dem Notepad-Editor von Windows!); natürlich sind vergleichbare Editoren ebenso dafür geeignet.
Update! Seit ca. der Version 7.xx werden einige Punkte des Menüs Kodierung in Notepad++ anders benannt.
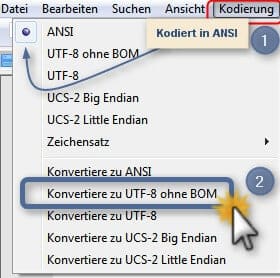
Bezeichnungen bis Notepad++ Version 6.9.x
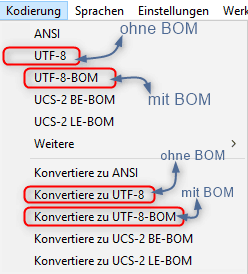
Bezeichnungen ab Notepad++ Version 7.x.x
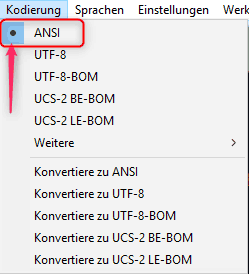
Kodierung des Dokumentes herausfinden
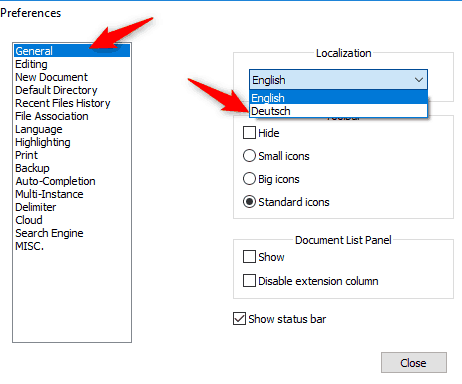
Zum besseren Verständnis: Die englischen Bezeichnungen
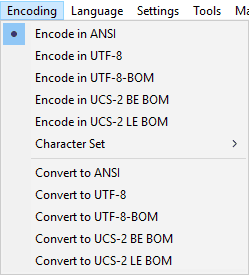
Kodieren (Encode) oder Konvertieren (Convert)?
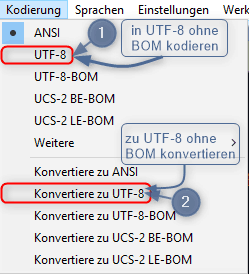
Um das geöffnete Dokument in UTF-8 ohne BOM zu konvertieren, klickt man auf Konvertiere zu UTF-8 (s. Punkt 2). Konvertieren (convert) sollte man immer dann, wenn das Dokument fehlerfrei angezeigt wird.
Anders verhält es sich, wenn Hieroglyphen oder sonstige komische Zeichen zu sehen sind. Dann sollte man auf UTF-8 klicken (s. Punkt 1), um die Datei in UTF-8 ohne BOM zu kodieren (encode).
Voreinstellung UTF-8 ohne BOM ab Notepad++ Version 7.x.x
Das war es auch schon. Wer öfters dererlei Dateien editiert und sich sicher ist, dass vorrangig die Kodierung UTF-8 ohne BOM benötigt wird, kann dies über den Menüpunkt Einstellungen -> Optionen -> Neues Dokument und dem Aktivieren von UTF-8 plus eventuell Auch beim Öffnen von ANSI-Dateien voreinstellen (s. nachfolgende Screenshots deutsch/englisch).
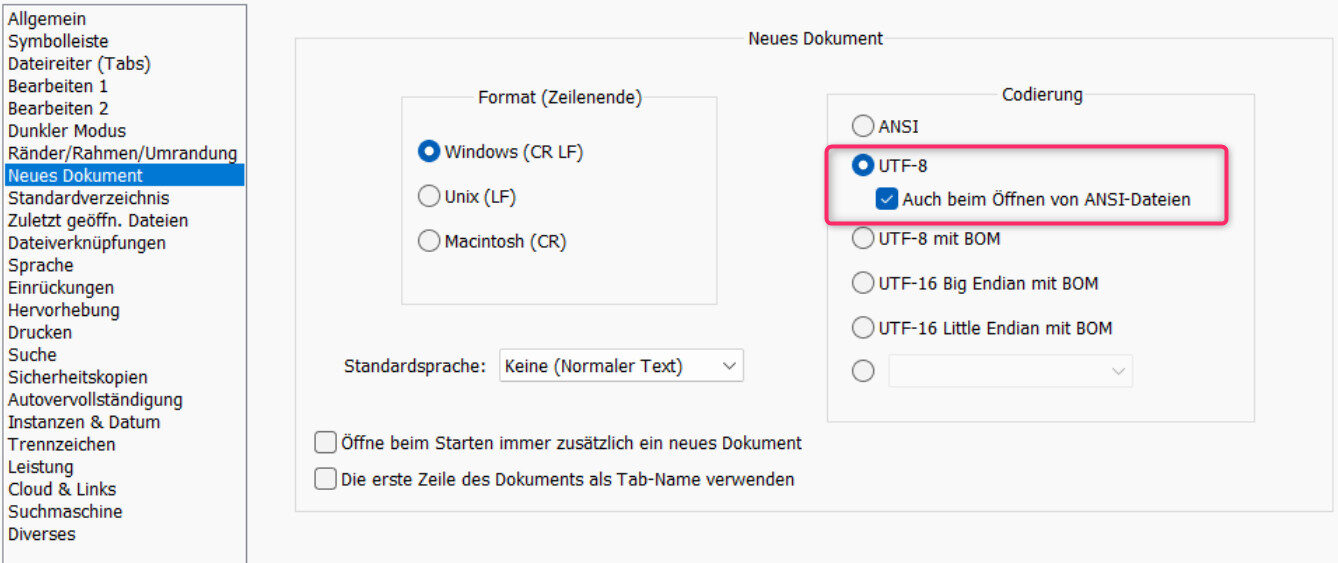
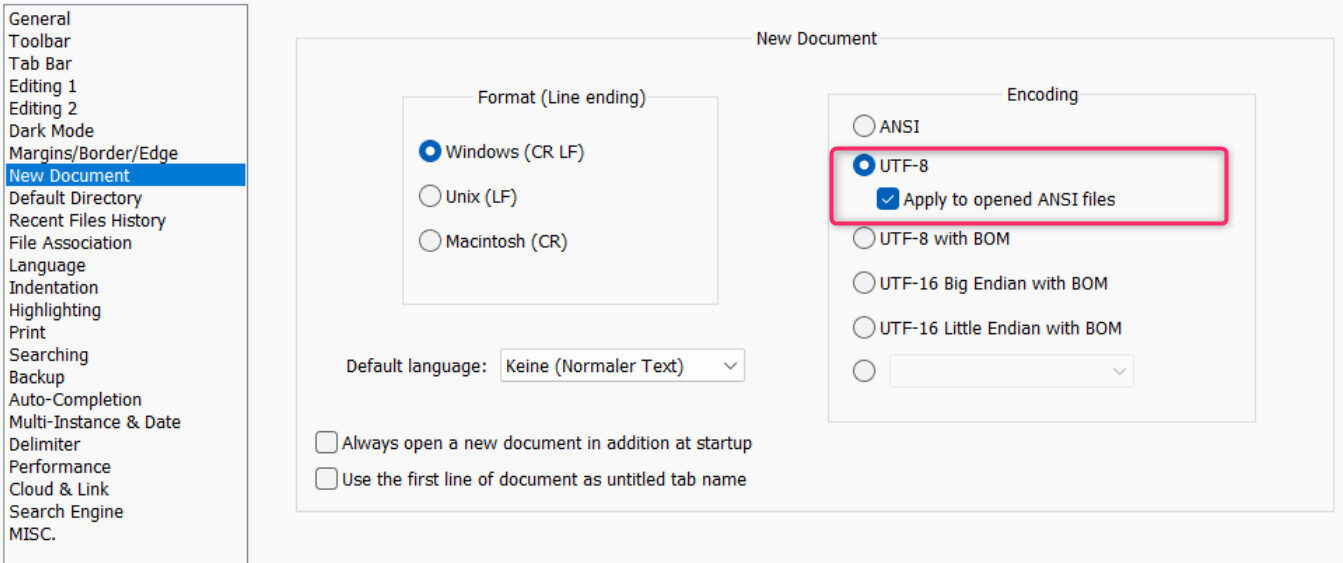
Voreinstellung UTF-8 ohne BOM bis Notepad++ Version 6.9.x
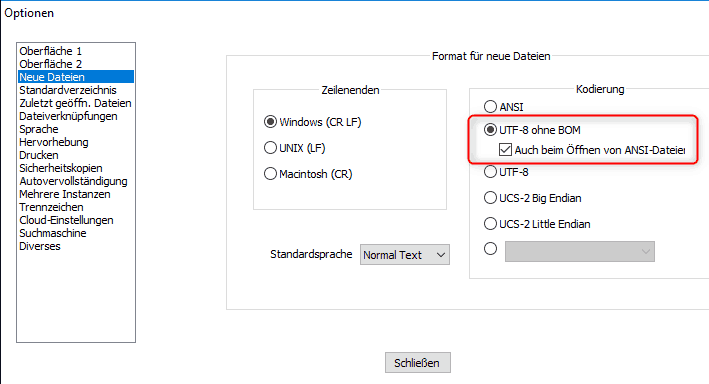
In Notepad++ bis Version 6.9.x kann dies über den Menüpunkt Einstellungen -> Optionen -> Neue Dateien und dem Aktivieren von UTF-8 ohne BOM plus eventuell Auch beim Öffnen von ANSI-Dateien eingestellt werden (s. nachfolgenden Screenshot).
Bonustipp:
Mit dem W3C Internationalization Checker kann eine Seite oder eine Datei auf ein vorhandenes BOM überprüft werden. Hier kann zum Beispiel im Fall von WordPress die .htaccess- oder die functions.php-Datei hochgeladen werden. Vom Hochladen der wp-config.php würde ich persönlich abraten, da diese serversensitive Daten enthält – es sei denn, die Datenbankdaten sowie die „Authentication unique keys and salts“ sind zuvor für diesen Test entfernt und die Datei ist wie oben beschrieben ohne BOM konvertiert worden. Das gilt für alle Arten von Dateien mit sensiblen Daten, auch außerhalb der WordPress-Blase.
Eine von W3C zur Verfügung gestellte Seite zeigt einen Text, der eine Leerzeile mit einem (unsichtbaren) BOM enthält. Dies kann mit der Eingabe der Seiten-URL im Checker geprüft werden.